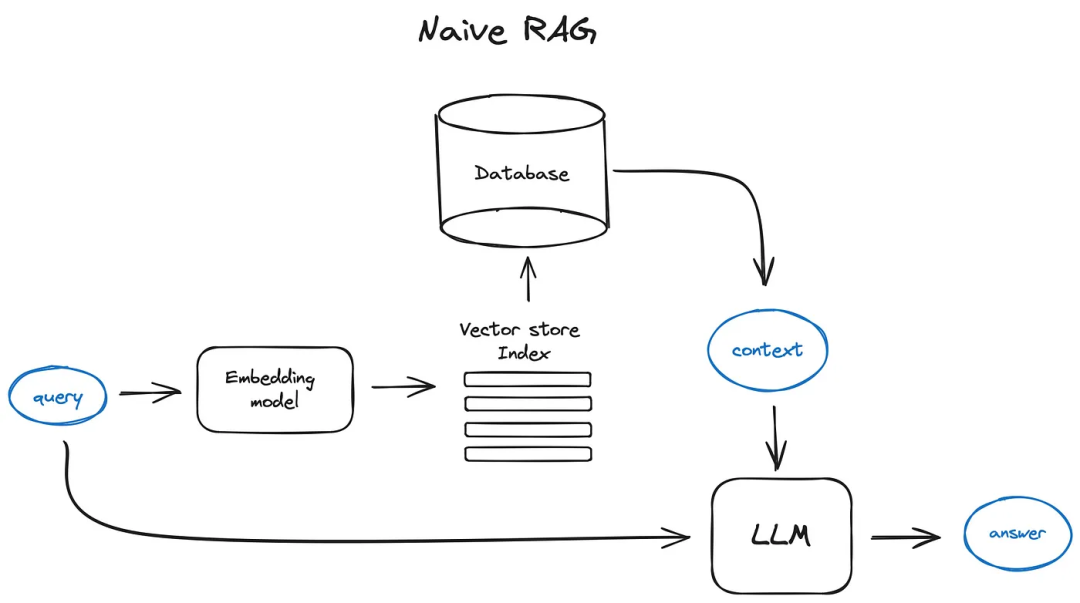
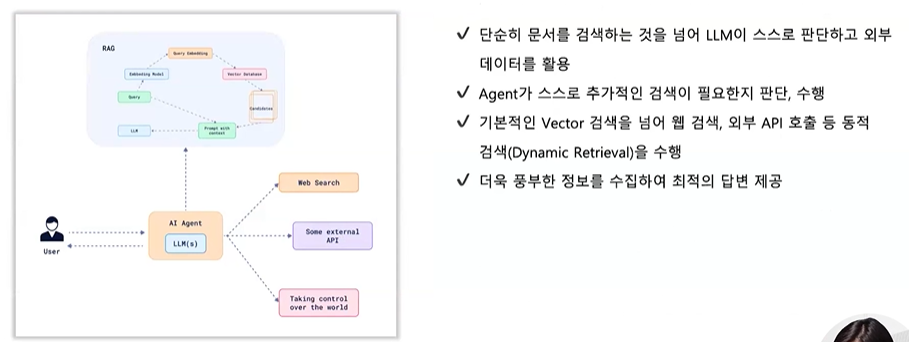
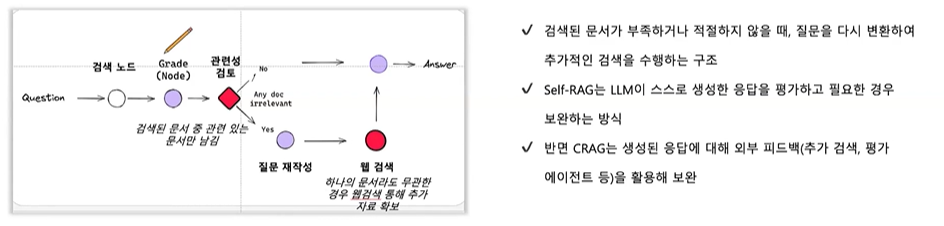
각 단계별 모듈의 내용을 앞으로 상황에 맞게 변경하면서 문서에 적합한 구조를 찾아갈 수 있습니다.
(각 단계별로 다양한 옵션을 설정하거나 새로운 기법을 적용할 수 있습니다.)
#전체 코드
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# 단계 1: 문서 로드(Load Documents)
loader = PyMuPDFLoader("./data/extract_text/AI_Paradigm_Shift_Driven_by_DeepSeek.pdf")
docs = loader.load()
# 단계 2: 문서 분할(Split Documents)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=50)
split_documents = text_splitter.split_documents(docs)
# 단계 3: 임베딩(Embedding) 생성
embeddings = AzureOpenAIEmbeddings(
model=AOAI_DEPLOY_EMBED_3_LARGE,
openai_api_version="2024-02-01",
api_key= AOAI_API_KEY,
azure_endpoint=AOAI_ENDPOINT
)
# 단계 4: DB 생성(Create DB) 및 저장
# 벡터스토어를 생성합니다.
vectorstore = FAISS.from_documents(documents=split_documents, embedding=embeddings)
# 단계 5: 검색기(Retriever) 생성
# 문서에 포함되어 있는 정보를 검색하고 생성합니다.
retriever = vectorstore.as_retriever()
# 단계 6: 프롬프트 생성(Create Prompt)
# 프롬프트를 생성합니다.
prompt = PromptTemplate.from_template(
"""You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Answer in Korean.
#Context:
{context}
#Question:
{question}
#Answer:"""
)
# 단계 7: 언어모델(LLM) 생성
# 모델(LLM) 을 생성합니다.
# ChatOpenAI 언어 모델을 초기화합니다. temperature는 0으로 설정합니다.
# ChatOpenAI 언어 모델을 초기화합니다. temperature는 0으로 설정합니다.
llm = AzureChatOpenAI(
openai_api_version="2024-02-01",
azure_deployment=AOAI_DEPLOY_GPT4O_MINI,
temperature=0.0,
api_key= AOAI_API_KEY,
azure_endpoint=AOAI_ENDPOINT
)
# 단계 8: 체인(Chain) 생성
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
prompt = PromptTemplate.from_template("""
You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question...
""")
처음 RAG 구조를 보면서 가장 인상 깊었던 것은 "AI도 참고서가 필요하다"는 점이었습니다. 아무리 똑똑한 AI라도 모든 정보를 기억할 수 없고, 특히 최신 정보나 특정 문서의 세부 내용은 알 수 없다는 현실적 한계를 인정하고, 이를 검색과 생성을 결합하여 해결한 아이디어가 매우 실용적이라고 생각했습니다.
복잡해 보이는 AI 시스템이 실제로는 상당히 접근 가능한 도구들로 구성되어 있다는 점이 놀라웠습니다. LangChain 같은 프레임워크 덕분에 대학생 수준에서도 충분히 이해하고 구현할 수 있는 수준까지 기술의 진입장벽이 낮아졌다고 느꼈습니다.
이 RAG 파이프라인을 통해 AI 엔지니어링의 핵심은 알고리즘 개발보다는 시스템 설계와 데이터 처리에 있다는 것을 깨달았습니다. 앞으로는 다양한 임베딩 기법, 벡터 검색 최적화, 프롬프트 엔지니어링 등을 더 깊이 공부해보고 싶습니다.
무엇보다 이런 기술을 실제 문제 해결에 어떻게 적용할 수 있을지 고민하며 실습 프로젝트를 진행해보는 것이 중요하다고 생각합니다.