
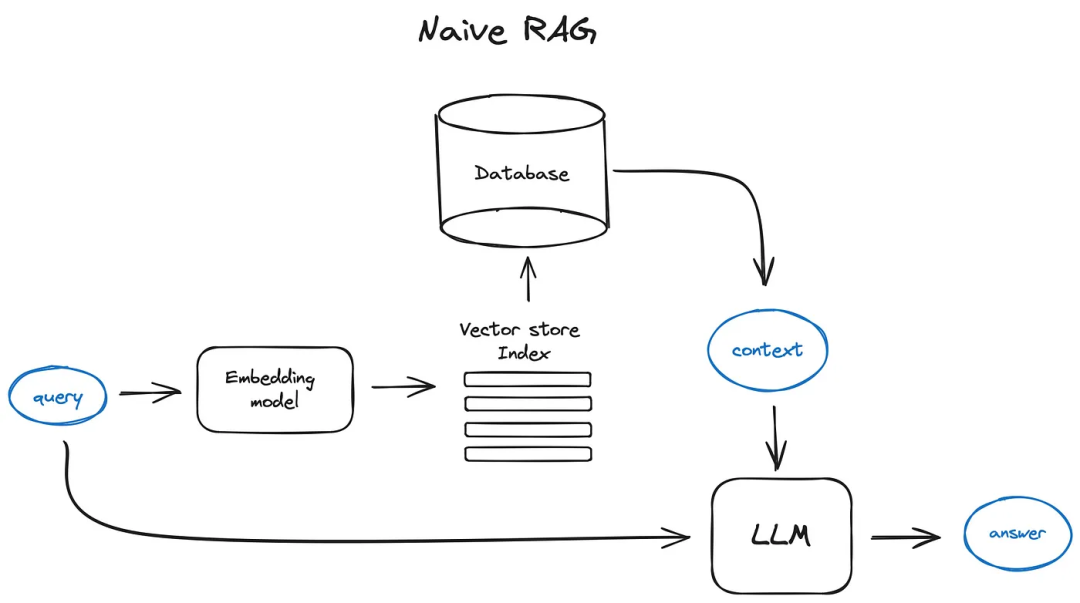
Naive RAG의 문제점

Advanced RAG

Evolution of RAG-based Systems: Naive RAG, Advanced RAG & Modular RAG | DrJulija's Notebook
🔹 Pre-Retrieval (검색 전 최적화)
목표: 좋은 인덱스와 데이터 구조 만들기
- 데이터 품질 개선: 불필요한 정보 제거, 모호성 해결, 사실성 검증, 최신화
- 인덱스 구조 최적화: 적절한 청크 크기, 그래프 구조 활용
- 메타데이터 추가: 날짜, 챕터, 목적 등 메타데이터 삽입 → 검색 필터링 강화
- 청크 최적화: 너무 크거나 작은 청크는 비효율적 → 문서 특성에 맞게 조정
주요 기법
- 슬라이딩 윈도우: 청크 간 겹침으로 맥락 유지
- 오토 머징 검색(Auto-Merging Retrieval): 작은 블록 검색 후 관련 블록 합쳐 제공
- 추상 임베딩(Abstract Embedding): 문서 요약(abstract) 기반 검색
- 메타데이터 필터링: 메타데이터 활용해 검색 정밀도↑
- 그래프 인덱싱: 엔티티와 관계를 그래프로 표현해 연관성 강화
🔹 Retrieval (검색 단계 최적화)
목표: 쿼리와 문서 청크의 의미 공간 정렬
- 도메인 지식 파인튜닝: 도메인 특화 데이터셋으로 임베딩 모델 개선
- 유사도 측정 최적화: 쿼리–청크 벡터 간 거리 계산 방식 선택
대표 유사도 지표
- 코사인 유사도(Cosine Similarity)
- 유클리드 거리(Euclidean Distance, L2)
- 내적(Dot Product)
- L2 제곱 거리(L2 Squared Distance)
- 맨해튼 거리(Manhattan Distance)
🔹 Post-Retrieval (검색 후 최적화)
목표: 불필요한 문서 제거하고, LLM이 효율적으로 활용하게 만들기
- 리랭킹(Reranking): 검색된 청크를 재정렬해 Top-K 관련성 높은 것만 사용
- 프롬프트 압축(Prompt Compression): 불필요한 맥락 제거, 요약을 통해 LLM에 전달할 컨텍스트 길이 축소
Modular RAG

개념:
Modular RAG는 Advanced RAG의 다양한 기법과 모듈을 조합해 전체 RAG 시스템의 성능을 높이는 표준적 패러다임.
각 모듈이 특정 기능을 담당하여 유연하고 확장성 있는 RAG 파이프라인을 구성할 수 있음.
📊 Modular RAG 정리표
| 단계 | 핵심 모듈 | 주요 기능 |
| Indexing | Chunk Optimization | 작은/큰 청크 최적화, 주변 문맥 포함 |
| Structural Organization | 문서를 섹션·단락·표 단위로 계층적 구조화, 지식 그래프 활용 | |
| Metadata 활용 | 카테고리, 날짜, 목적 등 메타데이터 기반 인덱싱 | |
| Pre-Retrieval | Query Transformation | 질문을 변형·재작성 (HyDE, 역-HyDE 등) |
| Query Expansion | 원 쿼리를 여러 서브쿼리로 확장 | |
| Query Construction | Text-to-SQL, Text-to-Cypher로 구조적 쿼리 생성 | |
| Retrieval | Retriever Fine-Tuning (FT) | LLM·도메인 데이터 기반 학습, Positive/Negative pair 훈련 |
| Retriever Source 다양화 | 문장, 청크, 문서, 엔티티, 서브그래프 단위 검색 | |
| Retriever Selection | 임베딩, 키워드, 하이브리드 검색 조합 | |
| Post-Retrieval | Rerank | 다양한 문서 유형(Code, Table 포함) 재정렬 |
| Compression | 긴 프롬프트 요약, 불필요한 정보 제거 | |
| Selection | LLM이 중요한 청크만 선택 | |
| Generation | Generator FT | 대규모 LLM 파인튜닝, 외부 지식 결합 |
| Verification | 사실 검증, 위키·지식 그래프 참조, 개인정보/헛소리 탐지 | |
| Extra Modules | Routing | 쿼리 성격 분석 후 적절한 파이프라인 분기 (요약 vs 검색 등) |
| Orchestration | 쿼리 → 판단(Judge) → 검색/생성 → 출력 흐름 제어 | |
| Scheduling | 필요 시 재검색을 반복하여 최적 결과 확보 | |
| Knowledge Guide | 지식 그래프 기반 추론 경로를 따라 검색 및 생성 |
✅ 한 줄 요약:
Modular RAG는 검색, 메모리, 퓨전, 라우팅 같은 모듈을 조합해 상황에 맞게 작동하는 유연한 RAG 시스템으로, 오늘날 RAG 애플리케이션의 표준 구조가 되었다.
Agentic RAG
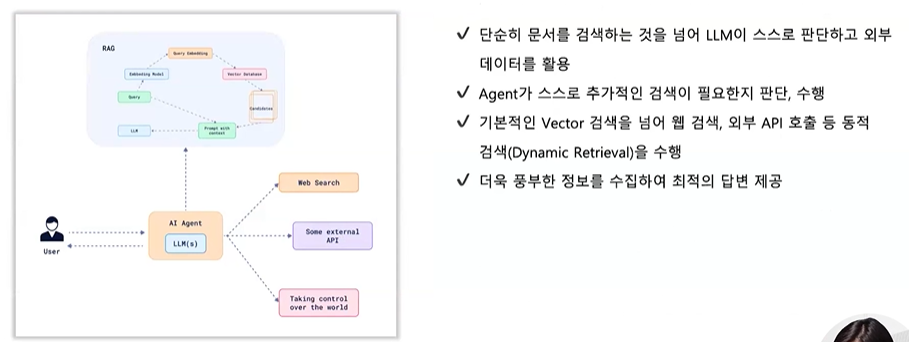
1. 정의 🤖
- 즉, LLM이 스스로 검색 전략을 결정하고, 필요한 경우 반복적으로 검색-추론-생성을 수행합니다. Agentic RAG는 LLM이 검색 전략을 스스로 설계하고 반복적으로 실행·검증하는 능동형 RAG로, 복잡한 질문과 불완전한 데이터 환경에서 특히 강력합니다.
2. 기존 RAG와의 차이
| 구분 | Naive/Advanced/Modular RAG | Agentic RAG |
| 역할 | 단순히 검색된 문서를 LLM 입력에 넣고 답변 생성 | LLM이 검색과 reasoning을 주도적으로 제어 |
| 검색 방식 | 고정된 Retriever, 정해진 파이프라인 | LLM이 "추가 검색 필요/필요 없음"을 판단 |
| 추론(Reasoning) | 주어진 문서 범위 내에서만 답 생성 | "계획 → 실행 → 검증" 루프를 통해 점진적 추론 |
| 강점 | 빠르고 단순 | 복잡한 질문에도 다단계 추론 가능, 더 정확한 답변 |
3. 핵심 아이디어
- 계획(Planning): LLM이 쿼리를 분석해 "무엇을 검색해야 하는가?"를 계획
- 행동(Action): 필요한 검색 요청을 수행 (예: 벡터DB, 웹 검색, SQL 쿼리 등)
- 검증(Verification): 가져온 문서가 유효한지/답변에 적합한지 확인
- 루프(Iteration): 필요하면 추가 검색을 반복
4. 주요 기술 요소
- Tool Use (도구 사용): LLM이 검색 엔진, DB, API 등을 직접 호출
- Self-Reflection (자기검증): "이 답변이 충분한가?"를 스스로 평가
- Adaptive Retrieval (적응형 검색): 단순 검색 vs 다단계 검색 여부를 상황에 따라 결정
- Multi-hop Reasoning (다단계 추론): 여러 검색을 연결해 복잡한 질문에 답변
Self RAG

1. 정의
- Self-RAG는 LLM이 스스로 검색 필요성과 활용 방식을 판단하고, 자기 반성을 통해 답변 품질을 높이는 RAG입니다.
2. 기존 RAG와 차이
| 구분 | 전통적 RAG | Self-RAG |
| 검색 방식 | 항상 쿼리 → 검색 → 답변 | LLM이 “검색 필요 여부”를 판단 |
| 흐름 | 고정된 파이프라인 | 유연한 파이프라인 (검색 생략 가능) |
| 출력 제어 | 검색 결과 기반 단일 답변 | 답변 전에 “이 답변은 신뢰 가능한가?”를 반성(reflect) |
| 장점 | 간단, 빠름 | 효율적(불필요한 검색 줄임), 정확성 ↑, 환각(hallucination) ↓ |
3. 핵심 아이디어
- 검색 필요성 판단: 쿼리만으로 답변 가능하면 검색 생략
- 자기 반성(Self-Reflection): LLM이 “내 답변이 근거에 맞는가?”를 검토
- 검색 활용 방식 선택:
- 검색 결과를 그대로 인용
- 여러 문서 비교 후 통합
- 혹은 무시하고 자체 지식 사용
4. Self-RAG 동작 과정 (간단 흐름도)
- 사용자 질문 입력
- LLM이 검색 필요 여부 판단
- 필요 → 벡터DB/검색엔진 호출
- 불필요 → 내부 지식 기반으로 답변
- 답변 초안 작성
- Self-Reflection: 답변이 충분히 근거 기반인지 점검
- 부족하다면 재검색 & 보완
- 최종 답변 생성
5. 장점
- 🔹 효율성: 불필요한 검색을 줄여 속도·비용 절약
- 🔹 정확성: 자기 검증 단계를 통해 잘못된 답변 감소
- 🔹 유연성: 질문의 난이도와 성격에 따라 검색 전략을 동적으로 조정
Corrective RAG
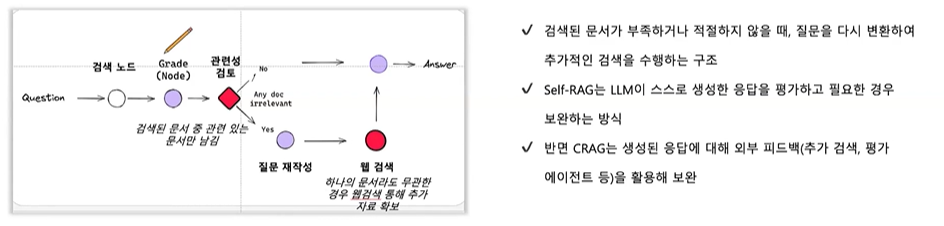
1. 정의
- Corrective RAG는 기존 RAG의 약점인 잘못된 검색 결과나 불필요한 맥락(노이즈) 문제를 보완하기 위한 기법이에요.
- 핵심은 LLM이 검색된 문서를 무조건 활용하는 것이 아니라, 오류를 감지하고 보정(correct)하는 과정을 포함한다는 점입니다.
2. 동작 원리
- 검색 단계
- 벡터DB/검색엔진에서 관련 청크를 가져옴
- 검증 단계(Validation)
- LLM이 검색된 문서의 정확성·관련성을 점검
- 불필요한 문서나 잘못된 정보를 필터링
- 보정 단계(Correction)
- 문서가 부족하거나 불완전하다면 추가 검색 수행
- 또는 LLM 자체 지식으로 보완 답변 생성
- 최종 응답 생성
- 신뢰할 수 있는 근거 위주로 답변
3. 주요 기법
- Answer Validation: 검색된 정보와 LLM 답변을 비교해 일치 여부 확인
- Hallucination Detection: 근거 없는 부분을 표시하거나 제거
- Iterative Retrieval: 검색 결과가 부족할 경우 반복 검색으로 보완
- Fallback Strategy: 검색이 실패했을 때 LLM 자체 지식이나 외부 소스를 활용
4. 기존 RAG와의 차이
| 구분 | Naive/Advanced RAG | Corrective RAG |
| 검색 활용 | 검색된 문서를 그대로 활용 | 검색 결과의 정확성·관련성을 점검 후 보정 |
| 오류 처리 | 문서 오류 → 그대로 답변 반영 위험 | 오류 감지 → 추가 검색 or 답변 수정 |
| 강점 | 단순, 빠름 | 더 신뢰성 있는 답변, 환각(hallucination) 감소 |
Adaptive RAG

1. 정의
- Adaptive RAG는 이름 그대로 질문과 상황에 맞게 검색 전략을 동적으로 조정하는 RAG 방식입니다.
- 한 가지 고정된 검색 방법을 쓰는 게 아니라, 쿼리 성격·난이도·응답 품질 요구에 따라 “검색할지 / 몇 개 검색할지 / 어떤 검색 방식을 쓸지”를 바꿔줍니다.
2. 동작 원리
- 쿼리 분석
- 질문이 단순 fact인지, 복합 reasoning인지 분류
- 예: “한국 대통령은 누구?” vs “2010년 이후 한국 대통령의 외교정책 변화를 요약해줘”
- 검색 전략 선택
- 간단한 질문 → 검색 안 하거나 Top-1 검색만
- 복잡한 질문 → 다중 쿼리 생성, Multi-hop 검색, 다양한 데이터소스 활용
- 동적 조정(Adaptation)
- 검색 결과가 불충분하면 추가 검색 반복
- 결과가 너무 많으면 필터링·요약 후 사용
3. 핵심 특징
- Adaptive Retrieval Depth
- 검색 단계를 1회만 할지, 반복적으로 할지 자동 결정
- Adaptive Chunk Selection
- 답변에 맞게 더 작은 청크 or 큰 문서 단위로 검색
- Adaptive Modality
- 텍스트뿐 아니라 필요 시 표, 그래프, 웹 검색 등 다른 소스 활용
4. 기존 RAG와 차이
| 구분 | 전통적 RAG | Adaptive RAG |
| 검색 방식 | 항상 동일한 방식 (Top-K 고정) | 질문·상황에 맞게 Top-K, multi-hop, 반복 검색 조정 |
| 효율성 | 불필요한 검색도 수행 | 최소 검색으로 효율 ↑ |
| 정확성 | 복잡한 질문엔 부족 | 질문 난이도에 맞는 전략 적용 → 정확성 ↑ |
📊 RAG 변형 기법 비교표
| 구분 | Self-RAG | Agentic RAG | Corrective RAG | Adaptive RAG |
| 핵심 개념 | LLM이 검색 필요 여부를 스스로 판단하고, 자기 반성(Self-reflection)으로 답변 품질 개선 | LLM이 에이전트처럼 능동적으로 검색 전략을 계획·실행·검증 | 검색 결과를 검증·보정하여 오류와 환각(Hallucination)을 줄임 | 질문 성격에 따라 검색 깊이·범위·방식을 동적으로 조정 |
| 검색 전략 | 검색 여부를 선택 (검색 vs 자체 지식) | 다단계(Multi-hop) 검색, 반복 검색 가능 | 검색 결과 재검증, 필요 시 추가 검색 | 단순 질문→간단 검색 / 복잡 질문→다중·반복 검색 |
| 주요 특징 | 불필요한 검색을 줄여 효율↑ | LLM이 검색·추론 전체를 제어 | 잘못된 검색 결과를 교정 | 상황 맞춤형 검색 전략으로 최적화 |
| 장점 | 비용·속도 절약, 정확성 ↑ | 복잡한 질문 처리, 추론력 강화 | 신뢰도 ↑, 오류·헛소리 감소 | 효율성과 정확성 동시 확보 |
| 예시 | “한국 대통령은 누구?” → 자체 지식으로 답, 검색 생략 | “2015년 이후 노벨상 주제?” → 연도별 검색·통합 | “아인슈타인 노벨상 연도?” → 잘못된 검색 교정 후 정확 답변 | “노벨상 연구 주제 요약” → 질문 난이도에 맞춰 검색 횟수·범위 조정 |
✅ 한 줄 요약
- Self-RAG → 검색 여부를 스스로 판단
- Agentic RAG → 검색·추론을 능동적으로 제어
- Corrective RAG → 잘못된 결과를 검증·보정
- Adaptive RAG → 질문 성격에 따라 검색 전략을 유연하게 조정
| 유형 | Self-RAG | Agentic RAG | Corrective RAG | Adaptive RAG |
| 검색 여부 | 필요할 때만 | 능동적 제어 | 오류 시 추가 검색 | 상황 따라 유연 조정 |
| LLM 역할 | 필요성 판단 + 자기검증 | 계획·실행·검증 루프 | 오류 감지·보정 | 전략 선택·최적화 |
| 강점 | 효율성↑ | 추론력↑ | 신뢰도↑ | 효율+정확성↑ |
'AI BootCamp > AI agent 스터디' 카테고리의 다른 글
| RAG project Insights (1) | 2025.09.14 |
|---|---|
| 수요일_RAG에 대해서(Generation) (1) | 2025.09.11 |
| 수요일_RAG에 대해서(Retriever) (0) | 2025.09.11 |
| 수요일_RAG에 대해서(Indexing) - OpenAIEmbeddings, Chroma, FAISS (0) | 2025.09.11 |
| 수요일_RAG에 대해서(Text Splitter) (0) | 2025.09.11 |