
SOTA 쉽게 달성 (State of Time Art) 최신 기술


https://huggingface.co/blog/fine-tune-whisper
-> reference

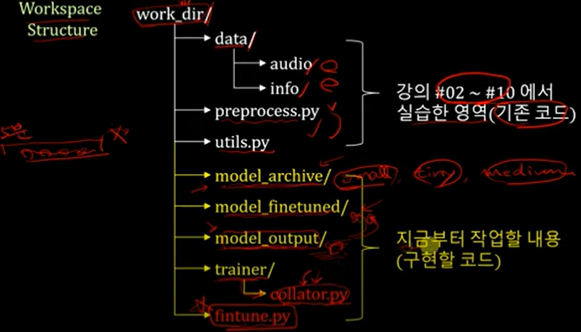
model_archive는 small, tiny, medium이든 학습시킬 whisper 배포 모델
model_fineruned : 파인 튜닝 5번 이후 저장되는 모델
model_output : 체크 포인트 3만번 이후에 저장
trainer : huggingface에서 copy&paste

mini batch로 조금씩 잘라서 feed-forward 학습을 시작한다
best model은 train 한 epoch이 끝난다음 validation하고 loss가 가장 작은 값인 모델

fine-tuning 1회시 순서도
interference.py는 실제 모델 돌릴때 필요하고, trainer.evaluate는 평가할 때 쓰인다

평가지표로는 CER을 많이 쓴다.
character error rate : 글자 하나하나가 의미가 있으므로 (조사)가 있어서
word error rate : 단어통으로 얼마나 에러가 있는지

7개의 메소드를 구현
'speechtotext' 카테고리의 다른 글
| [whisper fine tune] AIhub 데이터로 전이학습 - 2 (1) | 2024.09.22 |
|---|---|
| [whisper fine tune] AIhub 데이터로 전이학습 - 1 (0) | 2024.09.22 |